廣東口罩廠工人工資現(xiàn)狀及電信業(yè)務(wù)發(fā)展概況

近年來(lái),受全球經(jīng)濟(jì)形勢(shì)和產(chǎn)業(yè)結(jié)構(gòu)調(diào)整影響,廣東省部分傳統(tǒng)制造業(yè)工廠出現(xiàn)訂單波動(dòng),導(dǎo)致工人收入不穩(wěn)定。不過(guò),在疫情期間,口罩生產(chǎn)行業(yè)曾一度成為焦點(diǎn)。根據(jù)公開數(shù)據(jù)和實(shí)地調(diào)查,廣東省口罩廠工人通常實(shí)行計(jì)件或日薪制,普通生產(chǎn)線工人日薪約200-350元,技術(shù)崗位或加班情況下可達(dá)400元以上。工作強(qiáng)度方面,雖然流水線作業(yè)節(jié)奏較快,但多數(shù)工廠已優(yōu)化流程,工人普遍反映體力消耗在可接受范圍內(nèi),尤其相比建筑、搬運(yùn)等行業(yè)更為輕松。
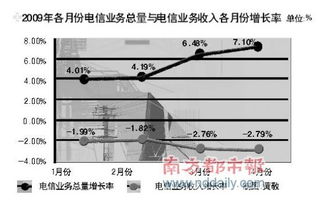
在電信業(yè)務(wù)領(lǐng)域,廣東省作為全國(guó)信息化建設(shè)領(lǐng)先省份,基礎(chǔ)電信業(yè)務(wù)(包括固定電話、移動(dòng)通信、寬帶接入等)在政策支持和市場(chǎng)需求推動(dòng)下保持穩(wěn)定增長(zhǎng)。工信部數(shù)據(jù)顯示,2022年廣東電信業(yè)務(wù)總量同比增長(zhǎng)約9%,5G網(wǎng)絡(luò)覆蓋和千兆光纖普及率居全國(guó)前列。這一趨勢(shì)為相關(guān)行業(yè)創(chuàng)造了大量就業(yè)崗位,如安裝維護(hù)、客戶服務(wù)等,部分崗位日薪可達(dá)300-500元,且穩(wěn)定性較高。
總體而言,廣東省制造業(yè)正經(jīng)歷轉(zhuǎn)型升級(jí),工人需關(guān)注行業(yè)動(dòng)態(tài)并提升技能以適應(yīng)變化;而電信等新興行業(yè)則展現(xiàn)出更強(qiáng)的抗風(fēng)險(xiǎn)能力和就業(yè)潛力。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.pocou.cn/product/2.html
更新時(shí)間:2026-06-18 22:02:12