2022年廣東省洗滌用品企業大數據全景分析 企業數量、競爭格局與投融資動態
一、行業背景與數據概覽
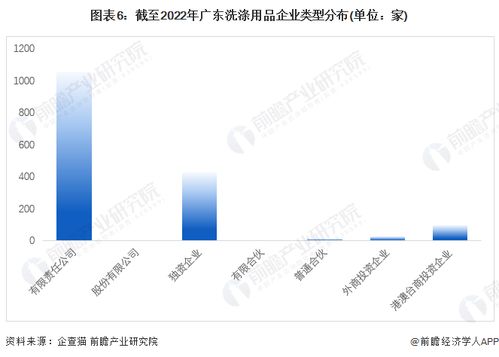
廣東省作為我國經濟大省和制造業中心,洗滌用品行業一直保持領先地位。根據2022年最新數據,廣東省洗滌用品企業數量達到約1,500家,占全國總量的18%左右,主要分布在廣州、深圳、佛山、東莞等珠三角城市。其中,大型企業(年銷售額超1億元)約占總數的10%,中小企業占據主導地位。行業整體呈現集群化、品牌化、綠色化發展趨勢,尤其在洗衣液、消毒液、家居清潔劑等細分領域增長顯著。
二、企業競爭格局分析
- 頭部企業優勢明顯:以立白、藍月亮、威萊集團等為代表的龍頭企業占據市場份額超過40%,在品牌影響力、渠道布局和研發投入上具有較強競爭力。立白集團作為本土日化巨頭,通過多元化產品線和供應鏈優化鞏固領先地位;藍月亮則專注高端液體洗滌市場,持續推動產品創新。
- 中小企業差異化競爭:眾多中小型企業通過細分市場切入,如專注母嬰洗滌、環保酵素清潔劑、酒店專用清潔產品等領域,依托電商平臺和區域渠道實現快速增長。佛山市、中山市等地形成了一批特色產業集群,通過產業鏈協同降低成本。
- 外資品牌與本土品牌交織:寶潔(廣州生產基地)、聯合利華等國際企業憑借高端產品和成熟營銷策略占據部分市場,但本土品牌在性價比和本地化服務方面更具優勢,尤其在三四線市場滲透率較高。
三、企業投融資動態
- 融資規模與方向:2022年廣東省洗滌用品行業披露融資事件約15起,總融資額超20億元,主要集中在A輪和戰略投資階段。資金流向呈現兩大特點:一是綠色技術與可降解材料研發項目受資本青睞,如生物酶制劑、植物基表面活性劑等領域;二是智能生產和數字化供應鏈升級成為投資熱點,多家企業獲融資用于自動化生產線改造。
- 并購重組活躍:行業整合加速,龍頭企業通過并購區域性品牌擴大市場份額。例如,立白集團旗下孵化平臺通過控股收購拓展母嬰護理板塊;部分外資企業也通過收購本土品牌加強渠道下沉。
- 政策與資本協同:廣東省“十四五”規劃對綠色日化產業的支持政策帶動了相關產業基金設立,地方政府引導基金與民營資本合作,重點投資循環包裝、節水型洗滌產品等創新項目。
四、關聯領域:廣東省基礎電信業務的影響
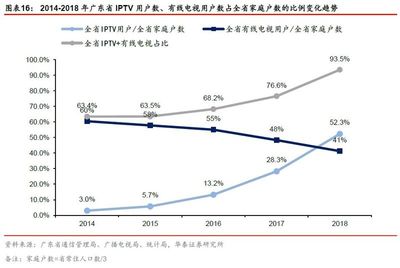
基礎電信業務的升級為洗滌用品行業帶來數字化轉型契機。廣東省作為全國5G網絡建設和千兆光網覆蓋的先行區,2022年全省基站總數超20萬座,企業寬帶接入速率同比提升30%。這推動洗滌用品行業在以下層面變革:
- 供應鏈智能化:物聯網技術應用于倉儲物流管理,企業通過實時數據監控優化庫存周轉;云平臺助力上下游企業協同生產,減少供需錯配。
- 營銷渠道創新:直播電商、社交電商依托高速網絡快速發展,中小品牌通過短視頻和私域流量運營突破區域限制。2022年廣東省洗滌用品線上銷售占比升至35%,較2021年增長5個百分點。
- 產品與服務融合:部分企業推出基于智能硬件的“清潔服務+產品訂閱”模式,如聯網智能洗衣設備配套專用洗滌劑,依托電信網絡實現遠程運維和消費數據分析。
五、挑戰與展望
盡管行業整體穩健發展,但仍面臨原材料價格波動、環保標準提升、同質化競爭加劇等挑戰。廣東省洗滌用品企業需進一步強化技術研發,深化綠色轉型,并利用數字基建優勢拓展全球化布局。基礎電信網絡的持續升級將為行業注入新動能,推動“產品制造”向“服務生態”演進。預計2023-2025年,行業集中度將進一步提升,創新型中小企業有望在細分賽道突圍,投融資活動更聚焦于可持續科技與模式創新。
如若轉載,請注明出處:http://www.pocou.cn/product/45.html
更新時間:2026-06-18 12:47:00