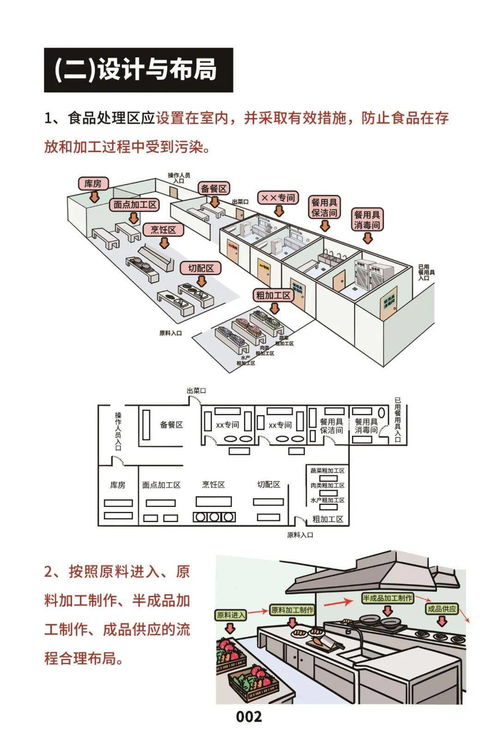
四川贊巴蜀食品 以極致性價比撬動美蛙魚底料市場

在競爭激烈的復合調味料市場,尤其是近年來風靡全國的美蛙魚頭火鍋賽道,四川贊巴蜀食品以其清晰的市場定位與獨特的經營策略,成功走出了一條以極致性價比征服市場的道路。其成功并非偶然,而是源于對餐飲供應鏈痛點的深刻洞察與系統性解決方案的構建。
一、精準定位:錨定大眾餐飲的“成本效率”核心訴求
贊巴蜀食品沒有盲目追求高端化或過度營銷,而是將目光聚焦于基數龐大、對成本高度敏感的中小餐飲商戶。這類客戶的核心需求是:在保證穩定口味與品質的基礎上,最大限度地降低采購成本、簡化后廚操作、提升出餐效率。贊巴蜀精準切入這一痛點,將產品定義為“餐飲后廚的效率解決方案”,而不僅僅是“一包底料”。通過優化供應鏈、規模化生產,將成本控制到極致,讓利給餐飲終端,使其能用更低的成本獲得不輸于知名品牌的風味穩定性,從而在B端市場建立了強大的吸引力。
二、產品內核:極致標準化與風味穩定性的統一
性價比不等于低質。贊巴蜀深諳此道,其征服市場的核心武器在于:
- 風味標準化:依托四川本土的原料優勢與成熟的研發能力,將經典美蛙魚鍋底的“麻、辣、鮮、香”進行科學量化與標準化復刻。確保每一批次產品風味高度一致,幫助餐飲店擺脫對廚師個人技術的依賴,實現“去廚師化”操作。
- 操作極簡化:設計“一料成菜”的便捷操作流程。餐飲商戶只需按比例加入水和食材,無需復雜調味,即可快速、穩定地呈現出口味地道的鍋底。這大幅降低了后廚的人工成本與技術門檻,尤其受到連鎖加盟店和初創餐飲品牌的青睞。
- 品質可視化的成本控制:在關鍵原料(如辣椒、花椒、豆瓣)上堅持使用優質產區產品,確保風味根基;通過集約化采購、優化生產工藝、精簡包裝等方式,在非核心成本環節極致壓縮,將每一分錢都花在“風味”刀刃上。
三、餐飲管理賦能:超越產品供應的價值延伸
贊巴蜀的競爭力不僅在于產品本身,更在于其為餐飲客戶提供的管理賦能:
- 成本管控方案:為客戶提供精準的用量測算與成本分析,幫助餐廳清晰掌握每一鍋菜品的原料成本,便于定價與利潤管理。
- 運營效率提升:標準化的操作流程縮短了備餐時間,提升了翻臺率,間接增加了餐廳營收。
- 風險規避:穩定的供應鏈和品質,避免了餐飲店因原料波動或口味不穩定導致的客戶流失風險。
- 輕資產運營支持:為意圖擴張的連鎖品牌提供了快速復制口味、實現標準化管理的基石,助力其輕裝上陣。
四、市場策略:渠道深耕與口碑裂變
在營銷上,贊巴蜀采用務實策略:
- 深度渠道合作:與大型餐飲供應鏈平臺、批發市場核心經銷商建立穩固合作,快速滲透至終端餐飲門店,確保產品觸達的廣度與效率。
- 樣板店打造:扶持一批使用其產品的成功餐飲門店作為“樣板”,用真實的火爆生意為產品效果背書,形成強大的示范效應。
- 口碑驅動:在B端市場,廚師和采購負責人的推薦至關重要。優秀的產品性價比和穩定的表現,自然在餐飲圈內形成了強有力的口碑傳播,實現了低成本、高信任度的市場裂變。
****
四川贊巴蜀食品的成功,本質上是供應鏈思維在餐飲調味品領域的勝利。它通過提供“高質、穩定、便捷、低成本”的極致性價比解決方案,精準滿足了大眾餐飲市場最迫切的需求,從而在美蛙魚底料這片紅海中開辟了屬于自己的藍海賽道。其模式證明,在餐飲工業化、標準化的大趨勢下,誰能真正為餐飲經營者降本增效、創造價值,誰就能贏得市場的持久青睞。
如若轉載,請注明出處:http://www.pocou.cn/product/34.html
更新時間:2026-06-19 14:30:35